单纯形方法的基本原理
为了引入计算线性规划的一般方法——单纯形方法,我们需要证明一些前置的命题.
书接上回,图解法给了我们一些直觉:
- 线性规划问题的解有四种:
- 有唯一解.
- 有无穷多有界解.
- 有无界解.
- 无解.
- 如果线性规划存在有界解,那么应该在凸可行域的顶点处.
但是这些结论尚且需要证明,但是在此之前,如果上述的结论都是正确的,那么求解线性规划就非常简单了,顶点是有限的,那么我们就能在有限的时间内得出答案.
凸集与顶点
定义:凸集
称一个集合 为凸集,如果对于任意的 以及 ,都有$$ \lambda x+ (1-\lambda) y\in D
这个概念在数学分析当中就已经阐述了,但是在最优化理论当中,凸集的性质是相当好的,我们之后的理论将会围绕凸集和凸函数进行.
定义:凸组合
设 是 中的 个点,称 为 的凸组合,这里 ,且 .
凸组合是线段的一个推广,给定 个点,其凸组合的全体构成的集合就是这些点构成的凸包(见下文).
定义:顶点
如果凸集某点 不存在另外两点 使得 为 的凸组合,则称 为该凸集的顶点.
顶点将会是我们接下来讨论的重要对象.
可行域为凸集
首先,对于二维线性规划的图解法,在绘图过程中我们可以发现可行域是不会出现凹四边形的,这就启发我们得出如下的结论.
定理:线性规划可行域凸
对于线性规划的标准形,其可行域为凸集.
证明: 设可行域为 考虑标准形:
首先对 ,有
且 是显然的,于是可行域 为凸集.
基可行解对应顶点
现在要证明一个重要结论,基可行解对应的就是凸集的顶点,这就使找到顶点的难度降低. 为证明这个结论,首先需要证明如下引理.
引理:可行解是基可行解的充要条件
可行解是基可行解等价于 正分量所对应的列向量是线性独立的.
证明: 结论是显然的,基可行解当中的正分量对应的向量就是基向量,从而是线性独立的.
设对应列向量分别为 ,考虑对 讨论.
当 时,说明该向量组已经是基向量组了,因此 就是基可行解.
当 时,这个向量没有达到 ,说明没有满秩,可以扩充到 个向量,从而化归到第一种情形.
定理:基可行解对应顶点
线性规划问题的基可行解 对应线性规划问题可行域的顶点.
证明:
先证明: 不是基可行解 不是可行域顶点.
根据引理, 正分量对应的列向量是线性相关的,也就是说存在不全为零的常数 :
此时对右式乘以 ,则
这两个对应的系数构成的解向量分别记为 ,当 充分小的时候,这两个向量都能落入可行域,即使得 对于任意 成立.
于是最后有
不是基可行解 不是可行域顶点.
当 不是可行域顶点时,说明存在 在可行域内使得
于是考虑对应的
那么
从而
而 是不全为零的,因此 不为基可行解.
存在基可行解为最优解
最后,单纯形法直接来源的结论是:存在一个基可行解为最优解,换言之,这对应了我们在图解法当中的直觉:最优解在凸集的顶点取到.
定理:最优解必在可行域顶点达到
若可行域有界,则存在一个基可行解是最优解.
注意
这个结论并不意味着最优解一定是基可行解,这个定理既不能保证基可行解一定是最优解,也不能保证最优解一定是基可行解.
证明: 假设我们找到了一个最优解 ,它如果不是基可行解,说明它不是顶点,则存在 和 ,使得
其中 为可行域.
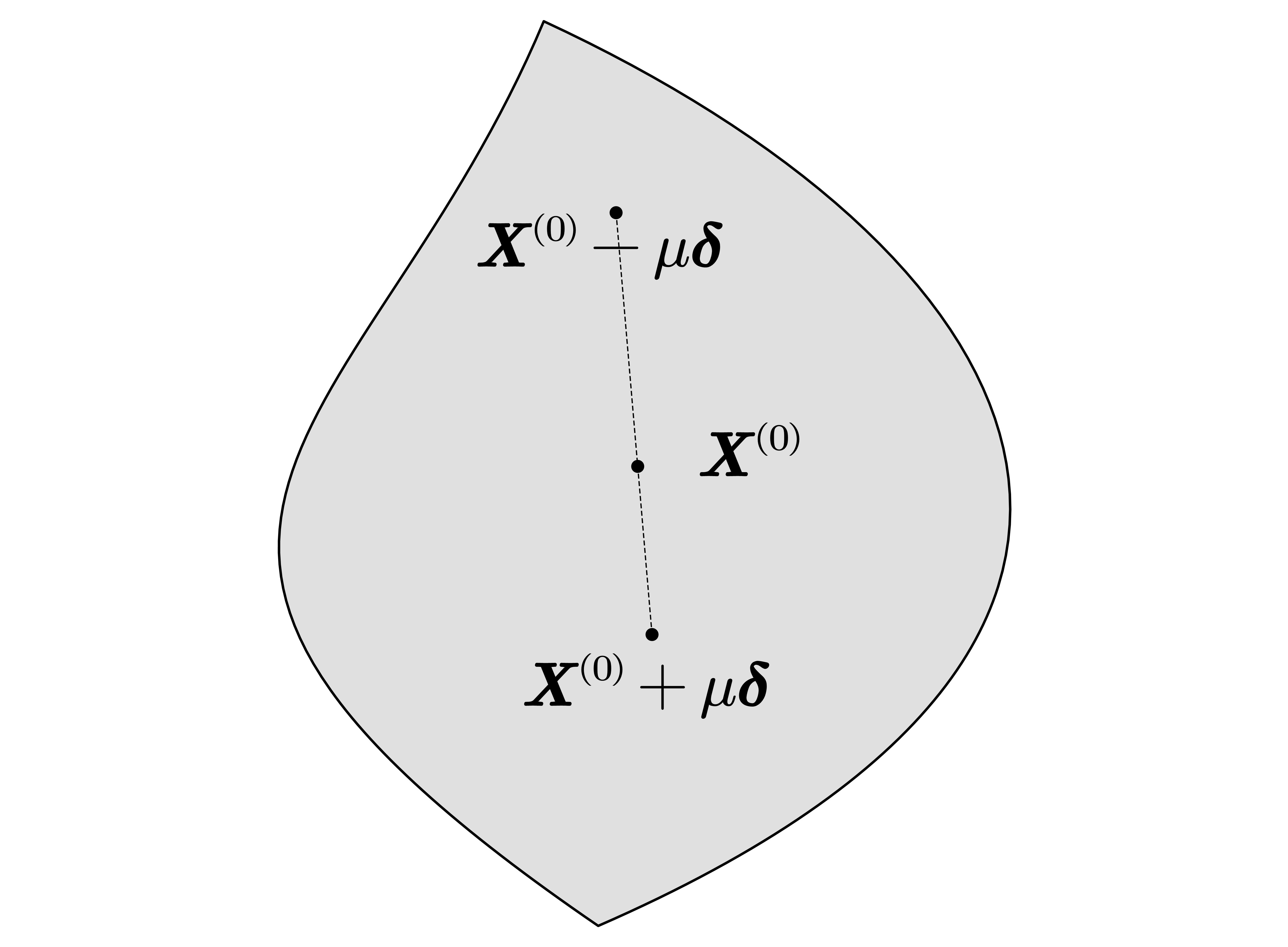
而根据最优解性质:
于是可得 . 换言之,每个经过最优解的线段如果交可行域于另外两点,这两点也将是最优解.
不断这样做下去,最终将会达到基可行解.
单纯形算法
注意
需要严格的理论证明的读者请参阅书本,这里仅仅给出直观的理解,尽量避免冗长的推导. 当然直观理解很容易出现胡说八道的情况,请酌情参考.
基变量表示
经过了冗长的理论证明,我们终于可以来到算法的部分,先从简单的例子开始来理解我们接下来的算法要打算干什么:
如果我们将问题改变为:
那么实际上就是将 作为基变量,然后目标函数就只剩下非基变量:
此时,我们称非基变量的系数为检验数. 然后令非基变量为 得到基可行解为 ,但是它是最优解吗?显然不是,因为我们可以看到,检验数还是 的,这就使得非基变量在增加时 仍会增加.
定义:检验数
将目标函数化为非基变量与常数的线性组合后,非基变量的系数称为检验数.
接下来微调上述例子再看,假如上述例子只改目标函数为
那么最终可以算出 ,也就是检验数为 ,这表明只要是可行解,就是最优解,也就是有无穷多最优解.
又改目标函数为
就可以计算出 是最优解,此时检验数都 .
以上例子说明,检验基可行解是不是最优解,只需要看检验数,我们把情况推向高维,有如下情况:
- 检验数 全部成立,说明达到最优解.
- 如果 对于某个 成立,且可通过 计算出 ,说明有无穷多最优解;
- 如果存在 ,说明当前的基可行解不是最优解,或是没有最优解(无界解).
这里面我们没有说到如何从一个基可行解转移到另一个基可行解,下面我们来讨论这一点.
出基和进基
从一组基可行解到另一组基可行解的原理很简单,就是从基变量中取出一个,然后放入一个非基变量形成一组新基. 还是刚刚的例子:
如果取 为基变量,则可以用 表示剩下的变量:
那么目标函数为:
检验数 ,因此基可行解就是 .
但是对于高维的问题,上述的方法直接写是不可行的,我们需要找到其中的规律. 假设检验数如下:
如果只存在一个大于 的检验数 ,那么对应的 显然就是进基变量,如果存在多个,那么对应的多个基变量到底应该选哪个进基呢?
答案是应该选最大的检验数对应的非基变量,因为它在目标函数当中最能影响目标函数的取值,因此我们不需要它.
接下来就是出基变量,由于我们已经知道了进基变量,不妨设为 ,对于某个基变量 ,由于我们可以表示为:
常数和非基变量的线性组合,我们现在希望的是从一个基可行解转到相邻的基可行解,而最能保证可行性的,一定是换出 最小的对应的 ,因为之后再用 表示 时,为 赋值为 给 可行性造成的影响最小.
单纯形算法与单纯形表
接下来终于可以将单纯形算法请出来了,以下的讲述会尽量避免过多的公式,反而影响直观的理解. 我们首先来看以下的一个例子:
化为标准形后为:
按照我们刚才已经证明的结论,我们首先要从系数矩阵里面解出基可行解:
我们可以看到一个单位矩阵,这种单位矩阵在之后将会是我们要重点关注的对象,我们总是假定存在这样的一个单位矩阵. 可以很轻易地看出 是一组基变量,因此我们可以列出如下的表格:
这个表格的第一行对应目标函数的系数,下面的 代表基变量, 代表对应所在的约束条件常数项, 代表基变量在目标函数当中的系数. 然后右下部分是变量在约束条件当中的系数值.
有了这些内容之后,我们要做的就是先确定进基变量,先计算检验数,有
这里是怎么计算的呢,是利用 计算得到的,例如对于 的检验数,就是计算
因此得到 为进基变量,出基变量如何操作呢?就是考虑 和进基变量各项系数比值的最小值(注意我们只考虑正值),即
对应的是 ,因此 出基,在单纯形上我们利用中括号标识出来:
然后我们在这个表的基础上继续往下写:
这个时候,我们需要做的一件事情就是利用我们刚刚替换的行进行行变换,然后消去 所在列其他行的元素,然后化为 .
注意这里的 也要变换,但 列不用参与变换. 此时继续下去还是利用 继续计算检验数:
此时只剩下一个进基变量, 进基, 出基. 依次进行下去即可.
退化现象
在计算过程中,有可能出现一种情况:在计算 最小值时,发现有多个出基变量对应到最小值,那么我们应该挑选哪个呢?
事实上可以任选,无论任选哪个,后面相关的出基变量都会取值为 ,这种现象叫做退化现象,也就是说最后的基可行解里有一个或多个基变量取值为 ,这个不是人为赋值的,而是计算得出的.